自动地,其背后的公司 WordPress 和 Tumblr 正在洽谈通过将其数据出售给人工智能公司(包括 MidJourney 和 OpenAI。该数据来自博客平台 Tumblr 和 WordPress.com 将用于培训 mode人工智能。
尽管交易细节尚不清楚,但这一消息引起了用户的担忧,担心这两个博客平台上的私人内容可能被滥用。 404 Media 还表示,Automattic 内部出现了内部冲突,因为收集的内容包括不打算保留在公司内部的私人数据。
为了应对这种强烈反对,Automattic 将推出一项新功能,允许用户选择不共享人工智能训练数据。该公司在一篇博客文章中重申了为 Tumblr 用户提供服务的承诺 WordPress 更好地控制其内容。它提到启动了“阻止人工智能公司探索”的设置,并解释说默认情况下会阻止领先的人工智能探索平台。
开发公司使用博客内容的问题 modele AI 不仅限于 Automattic 公司管理的平台。非常 OpenAI 像 Google 一样,使用 c-botraw我通过它从所有站点收集信息来训练 mode人工智能乐乐。该过程类似于搜索引擎收集数据。
你怎么能阻止 OpenAI 双子座(吟游诗人)从你的博客中获取数据?
如果您是博客或网站的所有者,并且不希望其中的数据用于培训 mode人工智能的 OpenAI 和双子座,你可以阻止机器人(crawlers)到内容。该限制可以通过文件设置 robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
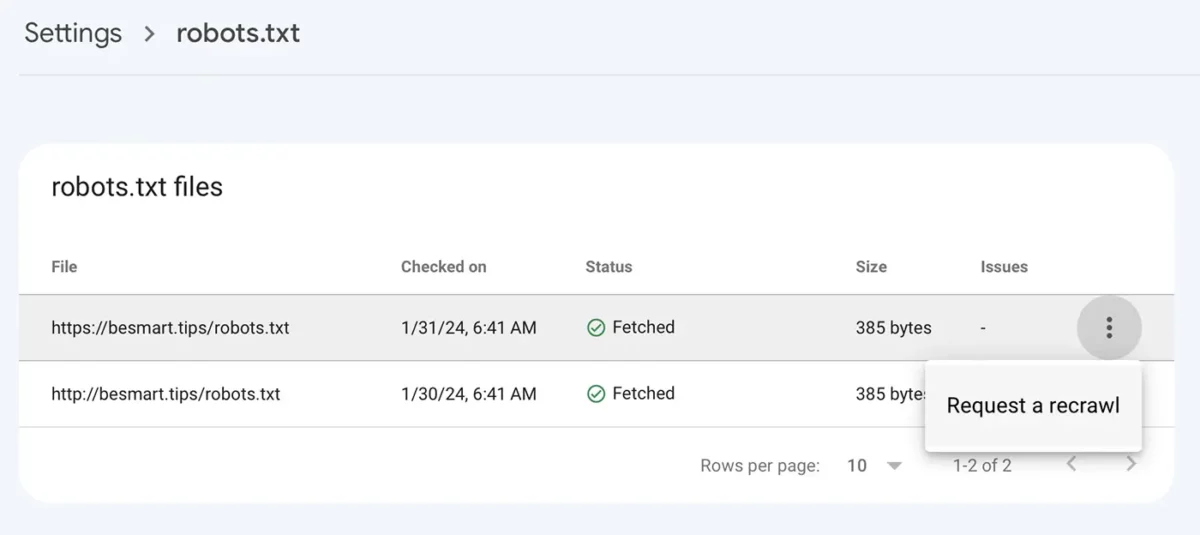
Disallow: /保存包含新行的 robots.txt 文件后,转到 Google Console 以: Settings > robots.txt > 单击带有三个点的菜单,单击“Request a recrawl“。
相关新闻: GPT-5 和由 OpenAI 开发的新网络爬虫 GPTBot。
对于 Tumblr 用户和 WordPress,从博客中检索数据的访问 OpenAI 或其他人工智能开发公司,将能够通过 Automattic 公司提供的工具进行阻止。