大多数时候,当您需要阻止访问时 SeekportBot 或其他人 crawl bots 对于网站,原因很简单。 网络蜘蛛在短时间内进行过多的访问并请求网络服务器的资源,或者它来自您不希望您的网站被索引的搜索引擎。
对c访问的网站非常有利raw我撞到了他。 这些网络蜘蛛旨在探索、处理和索引搜索引擎中的网页内容。 Google 和 Bing 使用这样的 craw我撞到了他。 但是,也有一些搜索引擎使用机器人从网页中收集数据。 Seekport 是这些搜索引擎之一,它使用 craw用于索引网页的 SeekportBot ler。 不幸的是,它有时会过度使用它并产生不必要的流量。
内容
什么是 SeekportBot?
SeekportBot 是 web crawler 公司开发的 Seekport,总部设在德国(但使用来自多个国家/地区的 IP,包括芬兰)。 该机器人用于抓取和索引网站,以便它们可以显示在搜索引擎结果中。 Seekport. 据我所知,这是一个不起作用的搜索引擎。 至少,它没有为我返回任何关键词的任何结果。
SeekportBot 使用 user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"如何阻止访问 SeekportBot 或其他 craw我点击了一个网站
如果您得出结论,这个网络蜘蛛或另一个网络蜘蛛没有必要扫描您的整个网站并向网络服务器造成不必要的流量,您可以使用多种方法来阻止它们的访问。
Web 服务器级别的防火墙
它们是防火墙应用程序 open-source 可以安装在操作系统上 Linux 并且可以配置为根据多个标准阻止流量。 IP 地址、位置、端口、协议或用户代理。
APF (Advanced Policy Firewall) 是这样一种软件,您可以通过它在服务器级别阻止不需要的机器人程序。
因为 SeekportBot 和其他网络蜘蛛使用多个 IP 块,最有效的块规则是基于“user agent”。 所以,如果你想阻止访问 SeekportBot 通过 APF,您所要做的就是通过以下方式连接到网络服务器 SSH,并在配置文件中添加过滤规则。
1.打开配置文件 nano (或其他出版商)。
sudo nano /etc/apf/conf.apf2. 寻找以“IG_TCP_CPORTS” 并在此行末尾添加您要阻止的用户代理,后跟一个逗号。 例如,如果你想阻止 user agent “SeekportBot",该行应如下所示:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. 保存文件并重启 APF 服务。
sudo systemctl restart apf.service“SeekportBot”访问将被阻止。
筛选 web crawls 在 Cloudflare 的帮助下 – 阻止 SeekportBot 的访问
在 Cloudflare 的帮助下,在我看来,这是最安全、最方便的方法,您可以通过它以各种方式限制某些机器人对网站的访问。 我在案例中也使用的方法 SeekportBot 过滤在线商店的流量。
假设您已经将网站添加到 Cloudflare 并激活了 DNS 服务(即网站的流量通过 Cloudflare),请按照以下步骤操作:
1. 打开您的 Clouflare 帐户并转到您要限制访问的网站。
2. 前往: Security → WAF 并添加一个新规则。 Create rule.
3. 为新规则选择一个名称, Field: User Agent – Operator: Contains – Value: SeekportBot (或其他机器人名称)– Choose action: Block – Deploy.
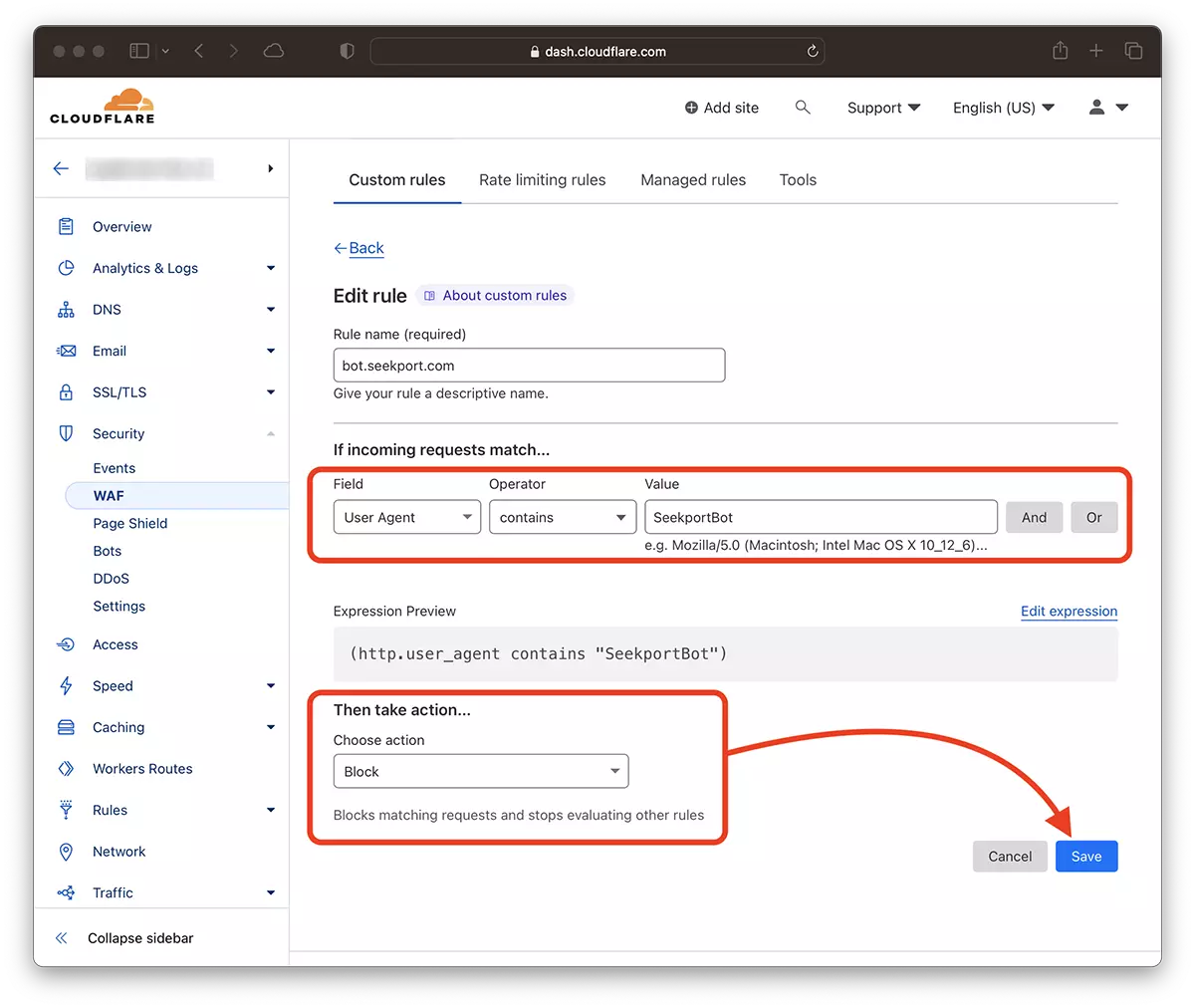
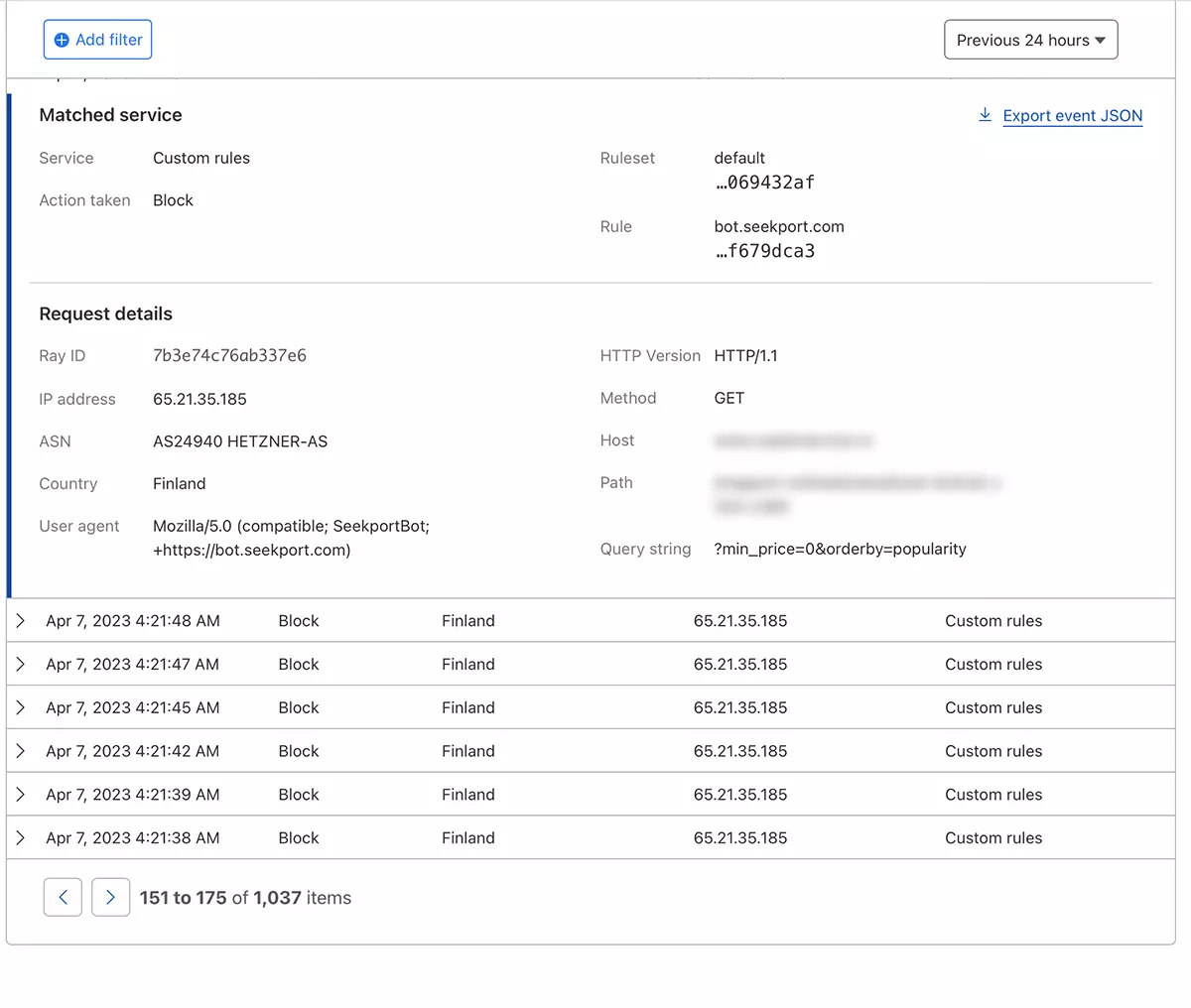
几秒钟后,新规则 WAF (Web Application Firewall) 它开始生效。
理论上,网络蜘蛛访问站点的频率可以设置为 robots.txt,但是……这只是理论上的。
User-agent: SeekportBot
Crawl-delay: 4许多 web crawlerii(Bing 和 Google 除外)不遵守这些规则。
总之,如果您确定一个网络 crawl 过度访问你网站的人,最好完全封锁他的访问。 当然,如果这个机器人不是来自您感兴趣的搜索引擎。